Træningsdata i AI: miniature eller dækning?
Der findes kunstig intelligens som kan lære at genkende både billeder og stemmer. Men hvordan lærer den egentlig – og hvad sker der, hvis de data, den er trænet på, viser en skævvridning af virkeligheden? I dette forløb skal I undersøge, hvordan maskinlæring virker, og hvorfor repræsentative data er vigtige.

Det lærer du
- At bruge begreber som ‘Miniature’ og ‘Dækning’ til at beskrive de data som bruges i maskinlæring
- At undersøge store datasæt ved brug af pivot-tabeller i regneark
- At kunne diskutere hvordan kunstig intelligens kan forbedres ved at optimere datasæt
Hvad og hvor meget skal printes:
Flashcards: 1 for hver elev, skal printes på begge sider af papiret.
Hunde og kager: Print et sæt for hver tredje elev i klassen, også på begge sider.
Elevark: Ikke obligatorisk, kan printes hvis der ønskes ekstra struktur i undersøgelsen af hunde og kager.
Klik-guide: Hjælpeark til arbejdet med pivot-tabeller, print 1 for hver anden elev. Print enten den til excel eller sheets alt efter hvilket program eleverne arbejder i.
Del 1: Maskinlæring
Maskinlæring i hverdagen
Maskinlæring bruges mange steder i vores hverdag, det bruges blandt andet til:
- Selvkørende biler, som blandt andet kan genkende biler, trafikskilte og fodgængere
- At hjælpe læger med at genkende sygdomme på fx røntgenbilleder
- Sprogmodeller som Google assistant eller Siri, så de forstår hvad du siger
Kan i komme på flere steder hvor maskinlæring bruges?

I skal nu i par prøve en maskinlæringsmodel, som ved at kigge på billeder kan kende forskel på chihuahuaer og muffins.
Opsamling i klassen: Hvor godt klarede modellen sig?
- Hvilke slags billeder var modellen bedst til at gætte rigtigt på?
- Hvad skete der, når I viste modellen billeder af ting, som den ikke var trænet på?
Men hvad er maskinlæring egentlig?
I skal nu se en video, som forklarer maskinlæring lidt nærmere. Tryk på linket herunder for at få adgang til videoen.
Når i har set videoen, skal i tage fat i de printede flashcards og gennemgå øvelse 2.
Del 2: Repræsentativitet i træningsdata
Repræsentativitet handler om, hvordan man udvælger et datasæt, så det afspejler den målgruppe, modellen skal anvendes på. Der er flere forskellige måder at udvælge et datasæt ud fra en befolkning, og 2 af dem skal I arbejde med nu.
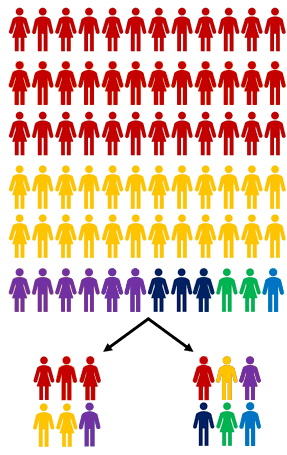
På billedet nedenfor ses to forskellige datasæt som er udvalgt fra den samme befolkning. Diskuter følgende i par:
- Hvordan er disse to grupper blevet udvalgt?
- Hvor stor en andel af hver farve optræder i befolkningen øverst i billedet og i hvert af datasættene?
- Hvilken af de to grupper repræsenterer befolkningen bedst?
Opsamling af svar i klassen
Hvad sker der, hvis man glemmer repræsentativitet?
I skal nu se et eksempel på, hvad der kan ske, hvis man ikke overvejer, hvordan ens datasæt skal udvælges. Se de første 43 sekunder af denne video:
Tal i klassen om hvad problemet
Opsamling i klassen:
- Hvad var problemet med maskinlæringsmodellen i videoen?
- Hvordan kan sådan et problem være opstået?
Mød forskeren
I har lige set, at det har stor betydning for en maskinlæringsmodel, hvordan man vælger at repræsentere sin befolkning i form af et datasæt. Forskeren Line Clemmensen har i sin forskning undersøgt netop dette.
Om Line Clemmensen
Line Clemmensen er professor i statistik på Københavns universitet og hun har forsket i de forskellige måder man kan vælge et datasæt på når man skal træne en maskinlæringsmodel. Målet med hendes forskning har været at kunne vælge det datasæt som gør modellen mest retfærdig.
På denne måde kan man forsøge at undgå problemer som det i blev præsenteret for i den video i lige har set.

To måder at udvælge datasæt
Når man udvælger et datasæt ud fra en befolkning, er der, som beskrevet længere oppe, flere måder at gøre det på. To af disse måder kalder man ‘miniature’ og ‘dækning’. Man kalder måder som disse repræsentationsformer, da hver repræsenterer den befolkning, man udvælger datasættet fra, på hver sin måde.
Miniature
Hvis man udvælger sit datasæt efter repræsentationsformen miniature, laver man et datasæt som ligner virkeligheden, bare mindre. Det betyder at man forsøger at bevare proportionerne i befolkningen man udvælger fra.
Hvis for eksempel 50% af befolkningen tilhører en bestemt gruppe så skal 50% af datasættet bestå af folk fra denne gruppe. Men da datasættet skal være mindre end befolkningen, kan grupper som består af få individer ende med at blive skåret fra.
Modellen der bliver trænet på et datasæt som er lavet efter repræsentationsformen miniature, lærer mere om de store grupper i datasættet end de små.
Til venstre kan i se en illustration af miniature, datasættet er en nedskaleret version af befolkningen, altså en miniature af befolkningen. Billedet er AI genereret
Dækning
Hvis man gerne vil undgå at minoriteterne befolkningen bliver skåret fra når man udvælger datasættet, så kan man bruge repræsentationsformen dækning. Her bevarer man ikke proportionerne af befolkningen, men har i stedet alle grupper i befolkningen med, og lige mange af hver gruppe.
Hvis man for eksempel inddeler en befolkning af danskere i grupper efter alder, så vil gruppen med 100-110 årige være meget lille i forhold til de andre grupper i befolkningen. Hvis man så udvælger et datasæt fra denne befolkning efter dækning, så vil der i datasættet være lige så mange danskere i gruppen 100-110 årige som i alle andre grupper.
Modellen der bliver trænet på et datasæt som er lavet med repræsentationsformen dækning lærer derfor lige meget om alle grupper i datasættet.
Til venstre kan i se en illustration af dækning, datasættet består af lige mange fra hver gruppe. Billedet er AI genereret.

Nu hvor I kender begreberne miniature og dækning, kan I måske genkende at billedet med de farvede personer i del 2 var udvalgt efter disse to principper.
- Hvilken af datasættene på billedet er udvalgt efter miniaturerepræsentationsformen?
Del 3: Line Clemmensens forskning
Nu skal I kigge på nogle af resultaterne fra Line Clemmensens forskning.
For at undersøge de forskellige måder at udvælge et dataset på trænede Line to maskinlæringsmodeller til at forudsige folks indkomst. Begge modeller blev trænet på datasæt fra Californien, men det ene datasæt var udvalgt efter miniature, mens det andet var udvalgt efter dækning. Målet var derefter at sammenligne de to modeller for at afklare deres styrker og svagheder.
For at sammenligne modellerne undersøgte hun, hvor gode de var til at forudsige folks indkomst i andre stater end Californien. Her testede hun dem både på stater, der ligner Californien, og på stater, der ikke gør. At en stat henholdsvis ligner og ikke ligner træningsdataene er bl.a. målt ud fra, om dem, der bor i staten, har samme alder, uddannelsesniveau og indkomst.
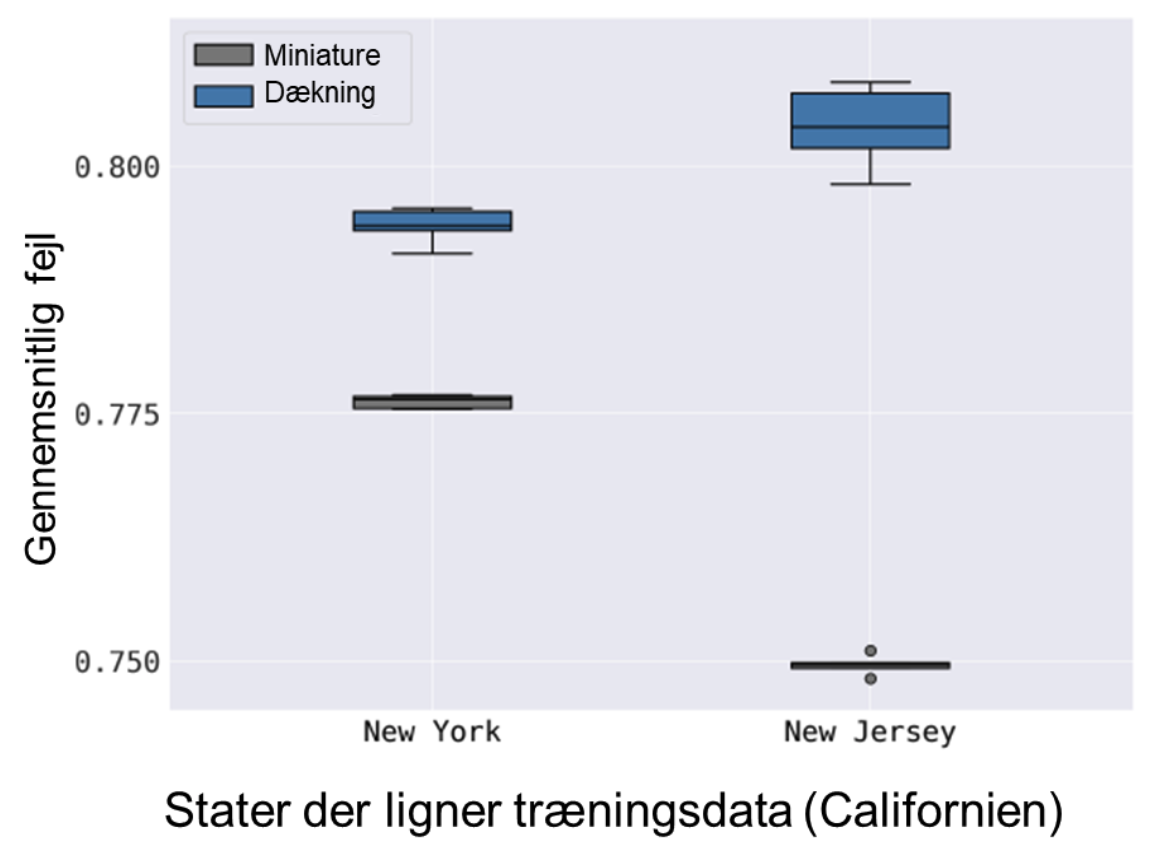
For at sammenligne resultaterne har Line udregnet modellernes gennemsnitlige fejl (altså hvor ofte modellen laver fejl i gennemsnit). Det betyder, at jo højere en gennemsnitlig fejl, jo værre har modellen klaret sig. For staterne New York og New Jersey, som ligner Californien, kan den gennemsnitlige fejl for de to modeller ses i følgende graf.
Hvordan klarer modellerne sig når data ligner træningsdata?
Modellerne har forudsagt lønindkomster i de to stater som ligner Californien.
- Hvilken type af repræsentativitet mener i har klaret det bedst?
- Hvordan kan i se at den har klaret sig bedst?
- Hvorfor tror i at den ene klarer sig bedre end den anden?
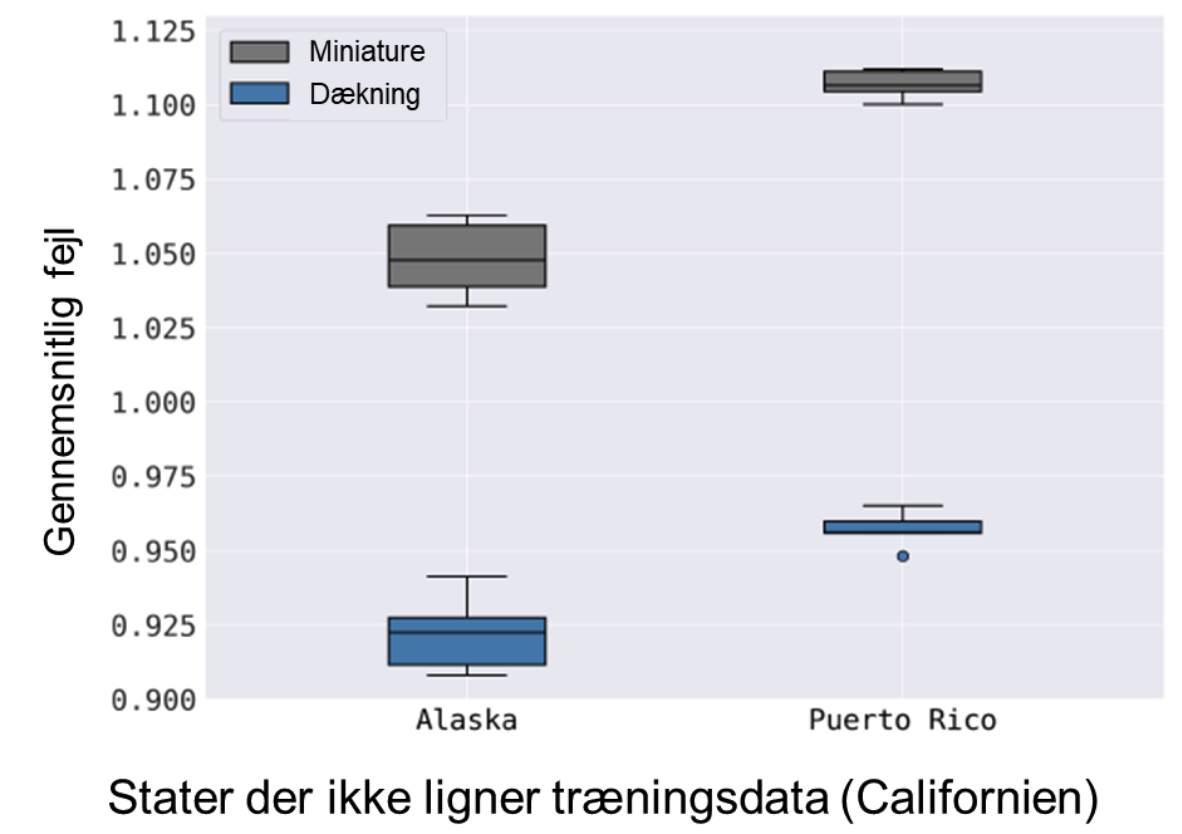
Line testede herefter modellerne på to stater, der ikke ligner Californien, nemlig Alaska og Puerto Rico. Resultaterne kan ses i grafen herunder.
Hvordan klarer modellerne sig når data IKKE ligner træningsdata?
Modellerne har forudsagt lønindkomster i de to stater som ikke ligner Californien.
- Hvilken af de to typer repræsentativitet mener i klarer sig bedst?
- Hvordan kan i se det?
- Hvorfor tror i at den klarer sig bedre?
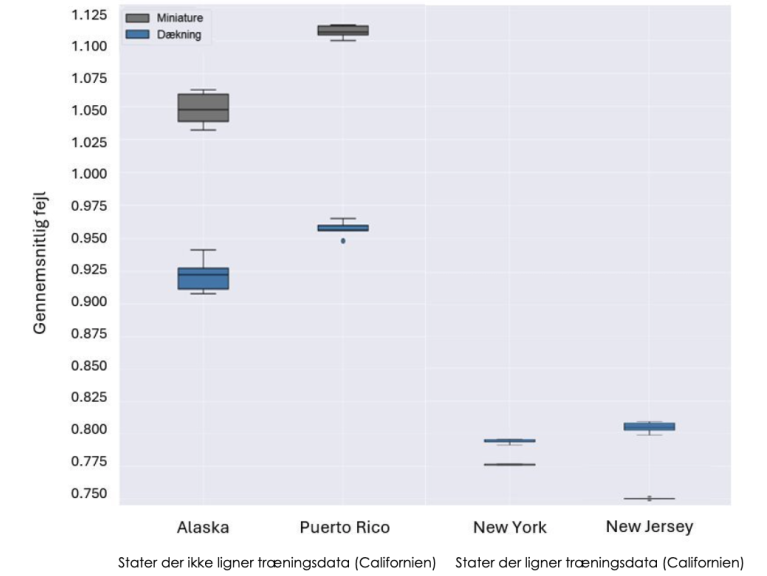
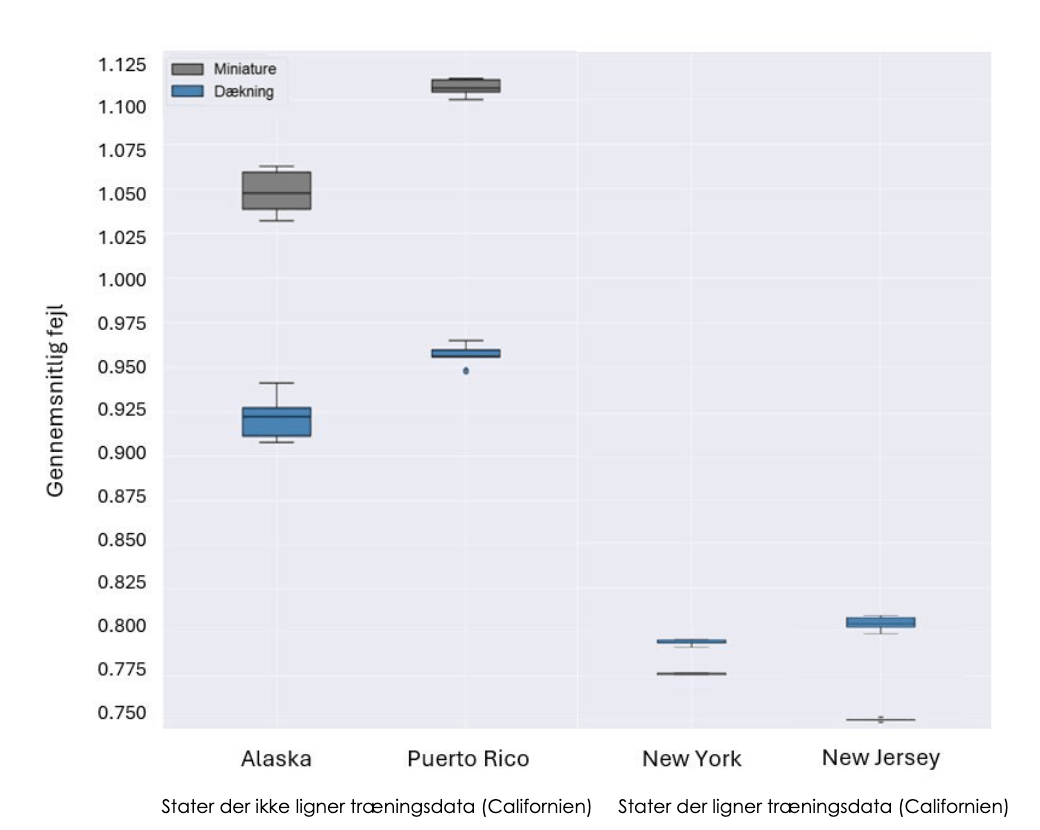
For at sammenligne resultaterne for New York og New Jersey med resultaterne for Alaska og Puerto Rico, har Line lavet en graf som viser dem alle. Den kan ses herunder.
Resultaterne samlet på én graf
Ud fra grafen kan man se at begge modeller klarer sig bedre på stater som ligner Californien end stater der ikke gør.
- Kan i forklare hvorfor?
Opsamling i klassen
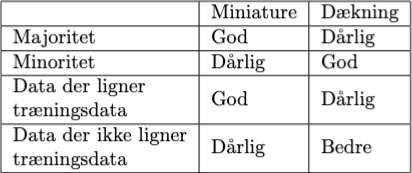
Øvelse 3: Hvornår er miniature bedre end dækning?
- Hvilken repræsentationsform skal man bruge hvis ens model skal være bedst til at gætte rigtigt på majoriteten af en befolkning?
- Hvilken en er bedre til minoriteter?
Hint:
Øvelse 3: Hvornår er miniature bedre end dækning?
- Hvilken repræsentations form er bedst til at gætte på data som ligner træningsdata?
- Hvilken en er bedst når det ikke gør?
Hint:
Øvelse 3: Hvornår er miniature bedre end dækning?
Ud fra jeres svar på spørgsmålene skulle i gerne være kommet frem til det følgende:
Del 4: Når patienterne bliver væk
Mange læger oplever problemer med, at patienterne bliver væk fra aftalerne. Se dette indslag fra der beskriver problemet, se kun de første 3 minutter og 23 sekunder:
I skal nu svare på Øvelse 4 i par.
Kan maskinlæring løse problemet?
Man har ude hos de praktiserende læger forsøgt at gøre problemet mere synligt; man har forsøgt at give bøder til patienter, der blev væk, og man har forsøgt at sende påmindelses-SMS’er. Ingen af disse forsøg har dog haft den ønskede virkning.
En ny løsning kunne være at træne en maskinlæringsmodel til at genkende de patienter, der typisk bliver væk, og hermed booke flere patienter til netop de tider. For at modellen bliver så god som muligt og fungerer efter hensigten, er der nogle ting, man bør overveje. Svar på følgende spørgsmål i par. Hint: Brug tabellen fra Øvelse 3.
- Hvad er vigtigst: at modellen gætter rigtigt for de fleste (majoriteten), eller at modellen er lige god til at forudsige udeblivelser i alle befolkningsgrupper?
- Hvad er det værste, der kan ske, hvis modellen gætter forkert?
- Skal modellen trænes med miniature eller dækning?
Herefter opsamling i klassen
Talegenkendelses modeller
I skal nu kigge nærmere på den type maskinlæringsmodeller, der kan genkende ord, når man taler til dem.
Mange ord på dansk udtales forskelligt alt efter hvor i landet man befinder sig. Det kalder man for dialekt. Ud over det kan man også udtale ord anderledes, fordi dansk ikke er ens modersmål; det kalder man accent. For at få et indblik i, hvor forskelligt vi taler i vores lille land, kan I se denne video fra DR P4 – Dialektskolen.
Accent og dialekt kan gøre det sværere at udvikle talegenkendelsesmodeller, der kan forstå alle former for dansk. Derfor arbejder projektet Doner Din Stemme med at indsamle stemmer fra så mange forskellige danskere som muligt. De vil gøre det nemmere at træne talegenkendelsesmodeller til at forstå dansk, hvilket kan gøre dem brugbare i flere dele af vores samfund end de er i dag.
Danskere kan frivilligt gå ind på donerdinstemme.dk og donere deres stemme. For at donere sin stemme skal man:
- Være over 15 år gammel
- Oplyse sit fødselsår, dialekt, køn og postnummer
Herefter skal man læse små tekster op, som bliver optaget og gemt hos Doner Din Stemme. Et eksempel på en tekst kunne være: “Hver dag starter Mette sin runde i en af byens parker. Hun tjekker, om stierne er rene, og om der er brug for at beskære buske og træer.“
Hvilken repræsentationsform?
- Diskuter i par, hvilken type repræsentation I mener Doner Din Stemme bør bruge til deres datasæt. Dækning eller miniature?
Del 5: Pivot tabeller
I skal nu undersøge Doner Din Stemmes datasæt. I skal gøre det i et regneark med det, der hedder pivottabeller. Pivot-tabeller er meget brugbare, når man skal undersøge store datasæt. For at I lige kan lære Pivot-tabellerne at kende, skal I først prøve at bruge dem på et mindre datasæt.
Først skal I se en kort video, der forklarer, hvordan man bruger pivottabeller.
Hvis i bruger Microsoft Excel skal i se denne video: https://tinyurl.com/4fr3fyev
Hvis i stedet bruger Google Sheets, skal i se denne video: https://tinyurl.com/yv66vfkh.
Nu skal I prøve det, der blev vist i videoen. Download dette regneark og løs opgaverne. Gå endelig tilbage og se videoen igen, hvis I er i tvivl.
Undersøg Doner Din Stemme datasættet
Nu er I klar til at undersøge datasættet fra Doner Din Stemme. I skal bruge det, I har lært af eksempelopgaverne.
Download først regnearket med datasættet her:
Doner Din Stemme bruger deres datasæt til at træne en talegenkendelsesmodel hos OpenAI. For at se, hvor godt modellen klarer sig, tæller de, hvor mange af ordene i en sætning modellen hører forkert, og udtrykker det som en procentuel fejl. Dette ses i datasættet som kolonnen “Fejl%”.
I skal nu undersøge, hvor god modellen er til at forstå dansk, alt efter hvem der taler.
Opsamling i klassen
Ud fra det i har lært og de tanker i har gjort jer i dette forløb skal I i klassen diskutere følgende
- Hvorfor er det vigtigt at være opmærksom på repræsentativitet, når man vælger træningsdata til maskinlæring?
- Hvilke situationer kan opstå, hvis man ignorerer kravet om repræsentativitet?
- Hvad er i jeres øjne fordelene og ulemperne ved at bruge Pivot-tabeller, når man arbejder med meget store datasæt?
Tak for denne gang!