Hvordan ved din streaming tjeneste hvad du vil se?
Du har sikkert prøvet, at en streamingtjeneste anbefaler dig en film, en serie eller en sang. Nogle gange rammer den plet, andre gange rammer den helt ved siden af. Men hvordan kan en algoritme egentlig gætte, hvad du gerne vil se eller høre? I dette forløb skal I undersøge, hvordan anbefalinger bliver til, og hvad der sker, når teknologi forsøger at forudsige jeres smag.

Print et elevark per 2 elever
Det lærer du
- At beregne afstanden mellem to punkter i et koordinatsystem
- At kunne opsamle og sortere data i et regneark
- At kunne beskrive og forstå to af de anbefalingsalgoritmer som bruges hos streaming tjenester; K-NN og A-NN
- At kunne omdanne sange eller film til punkter i et koordinatsystem
Del 1: Mød forskeren
Rasmus Pagh
Rasmus Pagh er professor i datalogi på Københavns Universitet.
Han forsker i datasikkerhed og maskinlæring, her i blandt hvordan algoritmer og datastrukturer fungerer.
Denne forskning har blandt andet gået ud på at undersøge hvordan anbefalingsalgoritmer fungerer og hvilke der er mest fair.

I skal nu i par lave en opgave som sætter jeres intuition omkring anbefalinger på prøve og diskutere hvordan streaming tjenester giver anbefalinger.
I skal bruge side 1 og 2 af de elevark jeres lærer udleverer.
Opsamling i klassen
- Snak om hvilke anbefalinger i har valgt og hvorfor.
- På hvilke punkter ligner de film i har valgt om den film, hhv. Lucca eller Charlie har set på forhånd?
Del 2: K-NN algoritmen
En af de anbefalingsalgoritmer som bruges af streaming tjenester hedder K-NN. I skal nu se en video om hvordan denne algoritme fungerer:
I skal nu i klassen diskutere følgende spørgsmål:
- Forklar med egne ord hvad K-NN-algoritmen gør, og hvordan den kan bruges til at lave anbefalinger? Hvad betyder K?
- I eksemplet bliver der kun brugt 2 akser til at beskrive filmene, hvad ville der ske med algoritmens evne til at anbefale fim hvis man brugte flere akser?
Gennemgang på tavlen: Hvordan laver man film om til punkter i et koordinatsystem?
Afstand mellem punkter i et koordinatsystem
Når i er færdige med øvelse 2, er jeres datasæt klar til at blive regnet på.
K-NN algoritmen bruger afstandene mellem punkterne i koordinatsystemet (datasættet) til at finde dem som ligger tættest og dermed ligner hinanden mest. Men hvordan finder man afstanden mellem punkter i et koordinatsystem?
Det kan være relativt nemt at se hvilke film der ligger tæt på hinanden når de er skrevet ind i et koordinatsystem, men da algoritmen ikke kan ‘se’ koordinatsystemet, er den nødt til at finde afstanden mellem punkterne kun ved brug af filmenes koordinater.
Dette gør den ved at bruge Pythagoras kendte læresætning a2 + b2 = c2.
Her er et eksempel på hvordan man kan udregne afstanden mellem 2 film i jeres koordinatsystem.
Eksempel: Afstanden mellem 2 film
Filmen ‘De utrolige’ kan ligge omkring 2 på kærlighedsskalaen og 8 på actionskalaen.
Det vil give filmen koordinaterne (2,8). Hvis vi kalder dette punkt i koordinatsystemet A vil vores koordinatsystem se sådan her ud:
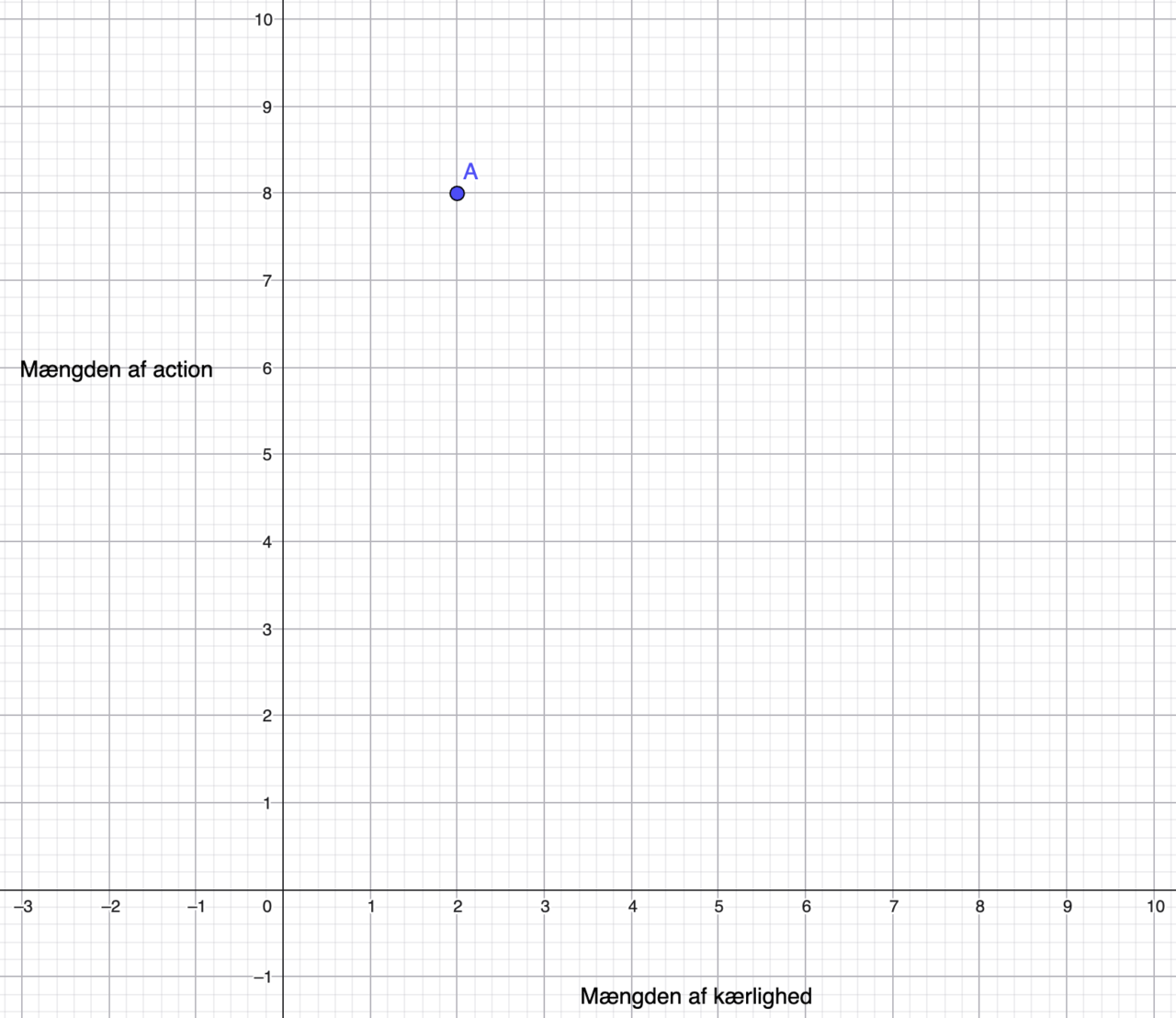
Eksempel: Afstanden mellem 2 film
Filmen ‘Skønheden og udyret’ kan ligge omkring 9 på kærlighedsskalaen og 3 på actionskalaen.
Vi kalder filmen B som får koordinaterne (9,3). Koordinatsystemet med begge film vil hermed se sådan her ud:
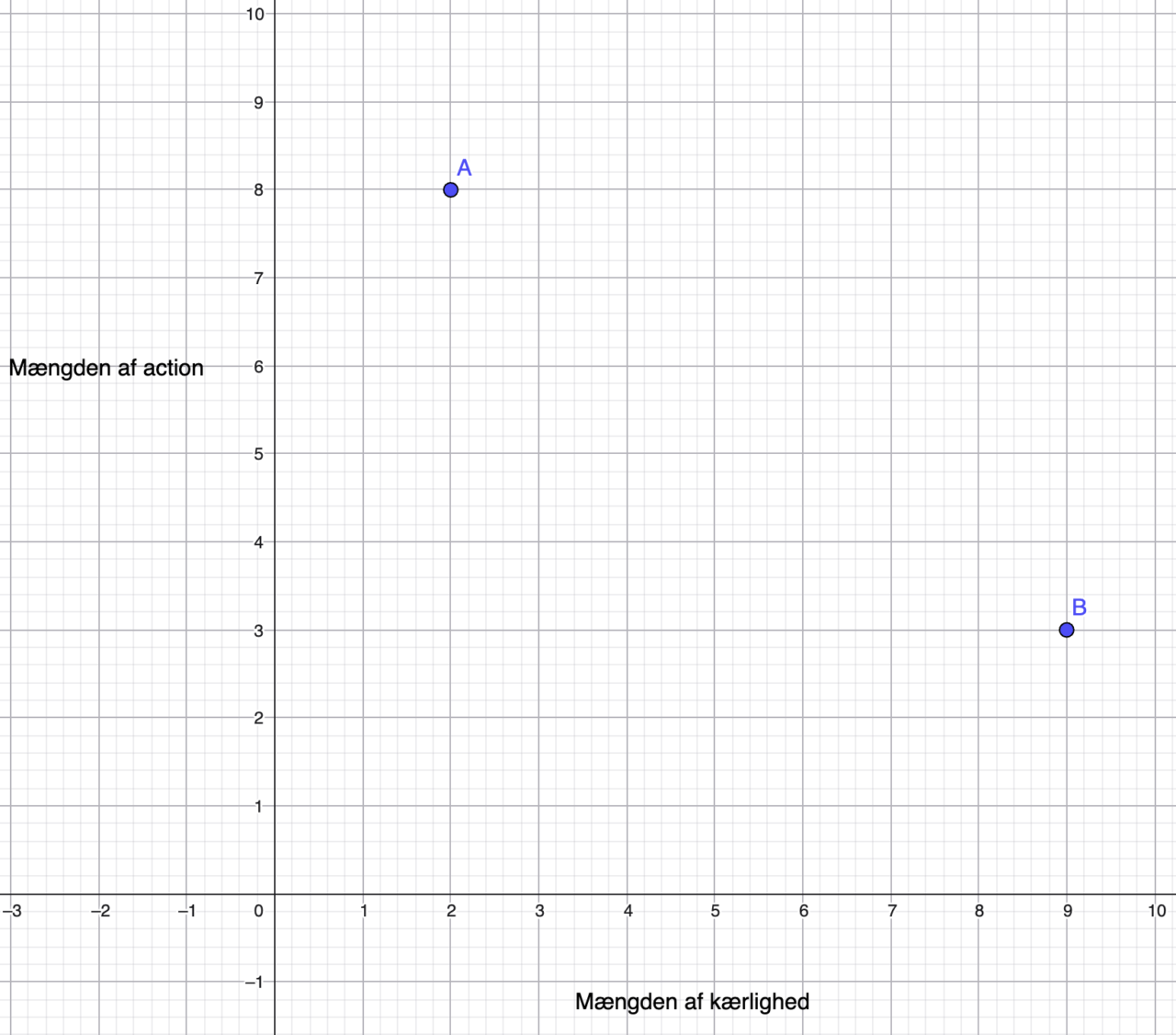
Eksempel: Afstanden mellem 2 film
For at bruge Pythagoras Læresætning, kan vi indtegne en retvinklet trekant mellem punkterne, for at finde afstanden mellem A og B skal vi dermed finde længden af linjestykke c (også kaldet hypotenusen):
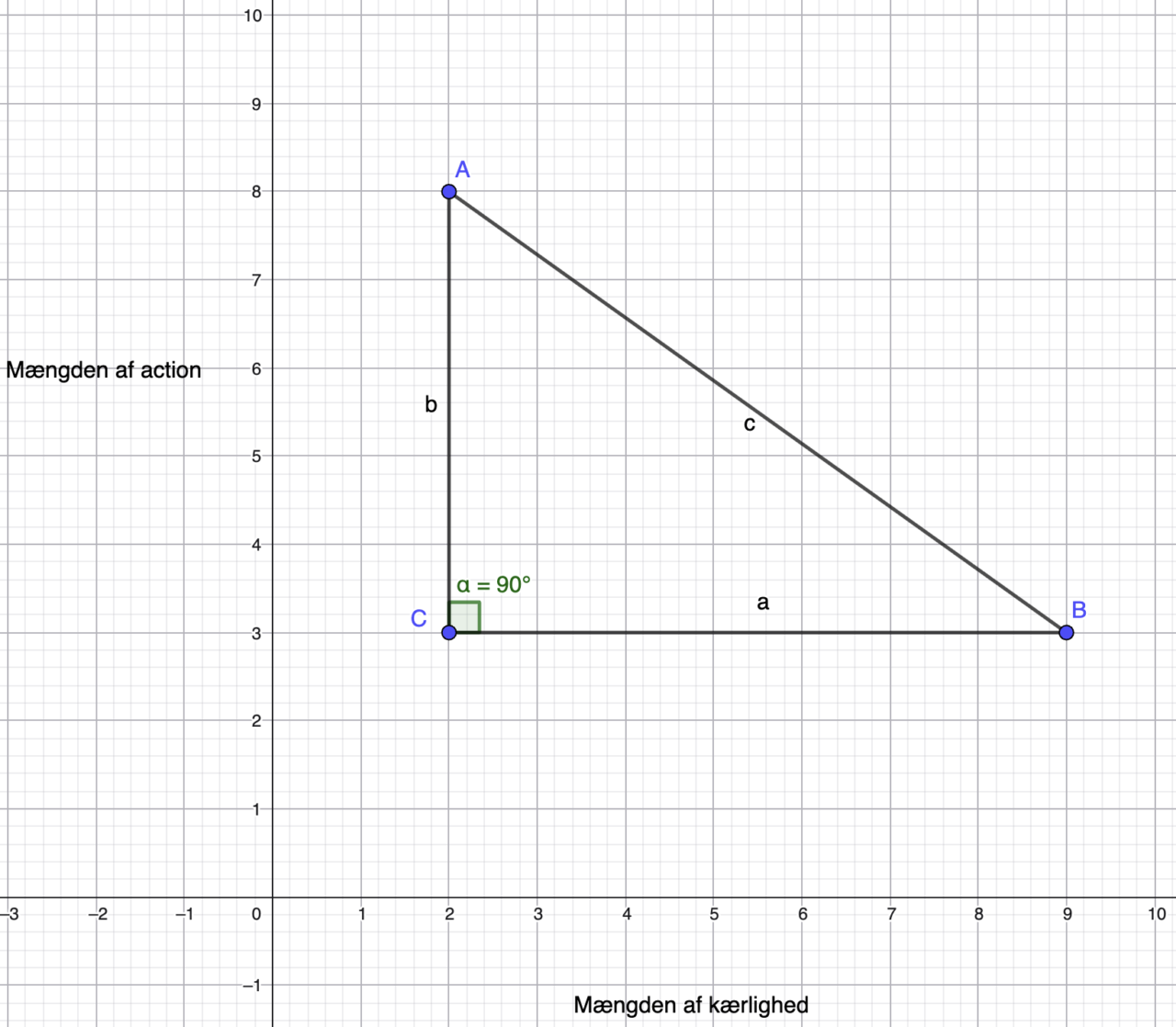
Eksempel: Afstanden mellem 2 film
Pythagoras Læresætning (set lige over dette eksempel) fortæller os, at længden af hypotenusen c kan findes ved brug af linjestykkerne a og b. Vi skal derfor først finde længderne af a og b.
Længden af a, er film B’s x koordinat, dette kalder vi Bx som er 9, minus film A’s x koordinat Ax som er 2. Derfor er a = Bx – Ax = 9 – 2 = 7.
Det samme gør vi for at finde længden af linjestykket b. b = Ay – By = 8 – 3 = 5.
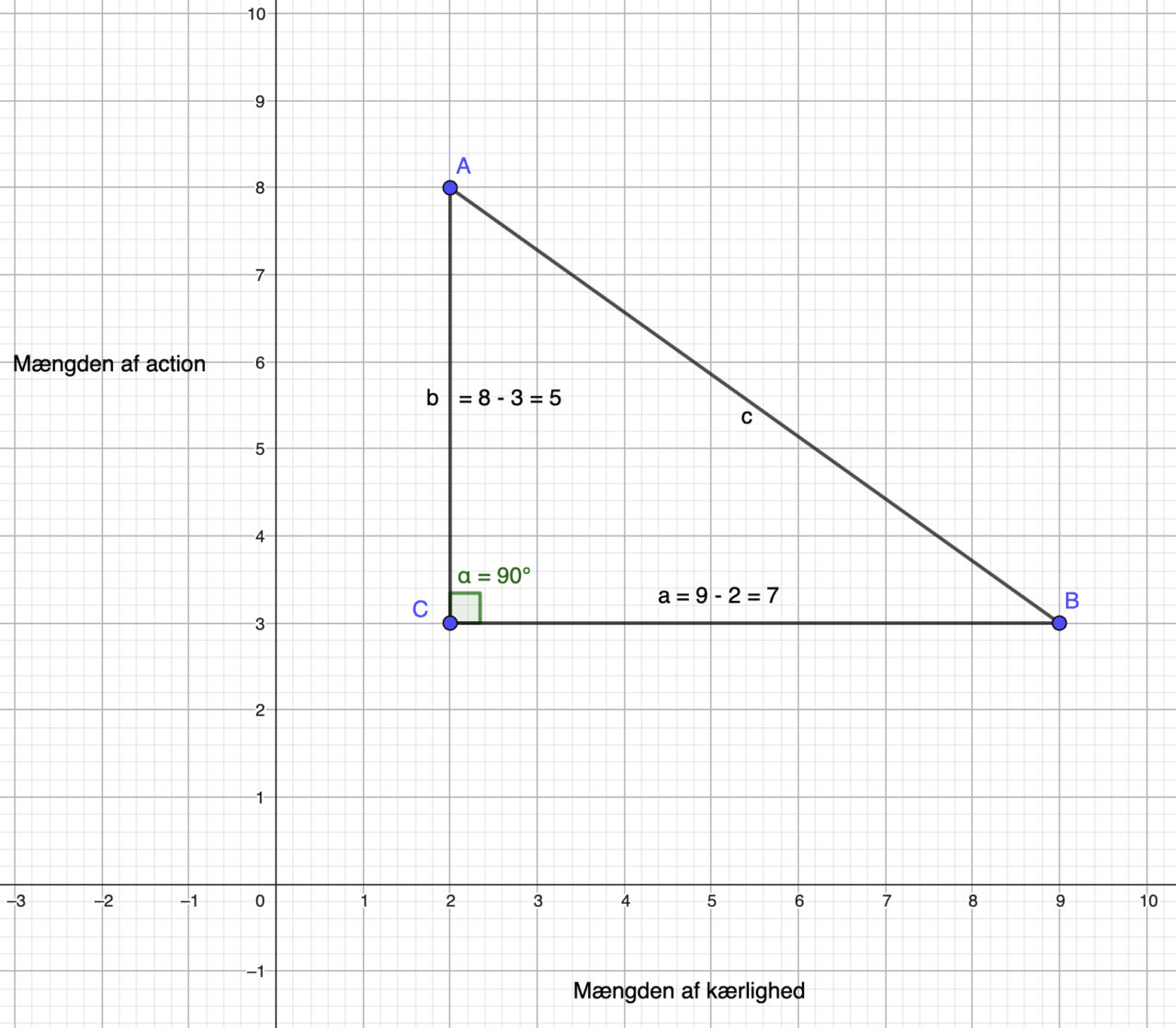
Nu kan vi bruge Pythagoras Læresætning til at finde længden af c.
a2 + b2 = c2 Vi indsætter længderne af a og b i formlen og tager kvadratroden: √(72 + 52) = c.
Vi kan nu udregne c: √(72 + 52) = √(49 + 25) = √(74) = 8,6 = c.
Afstanden mellem de to film er altså 8,6.
Prøv K-NN algoritmen
Nu skal i bruge Pythagoras Læresætning til at lave en anbefaling ud fra de film i har sat i jeres koordinatsystem.
K-NN algoritmen i praksis – Opsamling i klassen
- Hvordan gik det med at renge afstanden mellem punkterne?
- Syntes i at anbefalingerne var gode?
K-NN algoritmen er en meget præcis metode til at finde de punkter som ligger tættest i koordinatsystemet.
Hvis vores datasæt indeholder mange tusinder eller millioner af punkter og hvis vi bruger mere end bare 2 dimensioner til at beskrive punkterne, skal algoritmen lave den samme beregning rigtig mange gange hvilket kan gøre den langsom. Derfor arbejder dataloger som Rasmus Pagh aktivt på at udvikle nye algoritmer, som kan det samme som K-NN, bare hurtigere. En af disse skal vi kigge nærmere på nu.
Del 3: A-NN algoritmen
A-NN står for ‘Approximate Nearest Neighbor’ og betyder altså at den approximerer sig frem til det nærmeste punkt i koordinatsystemet. Dette gør den mindre præcis, men i store datasæt er den meget hurtigere end K-NN.
Se denne video for at høre mere om A-NN algoritmen:
Diskuter i klassen
- Hvordan fungerer A-NN algoritmen?
- Hvad er det der gør A-NN algoritmen hurtigere end K-NN?
Anbefalinger på spotify
På musiktjenesten Spotify findes der over 100 millioner sange. Der skal derfor en effektiv anbefalings-algoritme til for at din hjemmeskærm på Spotify kan genereres på et split-sekund.
Dette gøres ved, at hver enkelt sang får værdier indenfor bestemte kategorier. Der er mange forskellige kategorier, men i dette forløb fokuserer vi på to:
Happiness
Danceability
Prøv A-NN algoritmen
Vi har fundet et datasæt med de mest afspillede sange på Spotify i 2023. Datasættet er filtreret så det kun er sange med titler på ét ord som er udgivet af én kunstner der er med.
Sangene er lagt ind i et koordinatsystem efter deres Happiness og Danceability. Dette koordinatsystem kan findes i denne Geogebra fil:
I skal i opgaven notere hvilke sange der ligger i samme ‘kasse’, til dette skal i bruge følgende regneark:
Nu er i klar til at gå i gang med Øvelse 4
For at sortere data i en tabel skal man starte med at markere hele tabellen.
Herefter skal man trykke på ‘Data’ oppe i toppen af regnearket.
Så dukker der en knap op som hedder ‘Sort’ eller ‘Sorter’, tryk på den.
Man kan nu vælge hvilken kolonne i regnearket der skal sorteres efter og hvad rækkefølgen skal være.
Snak i grupper
- Hvilken sang valgte I?
- Er ANN-algoritmens anbefaling faktisk den sang, der ligger nærmest?
- Kunne nummer 2 eller 3 på listen være en ligeså god anbefaling?
Modeleringscyklussen
Gennemgå den overordnede ide og de enkelte faser af modelleringscyklussen i klassen
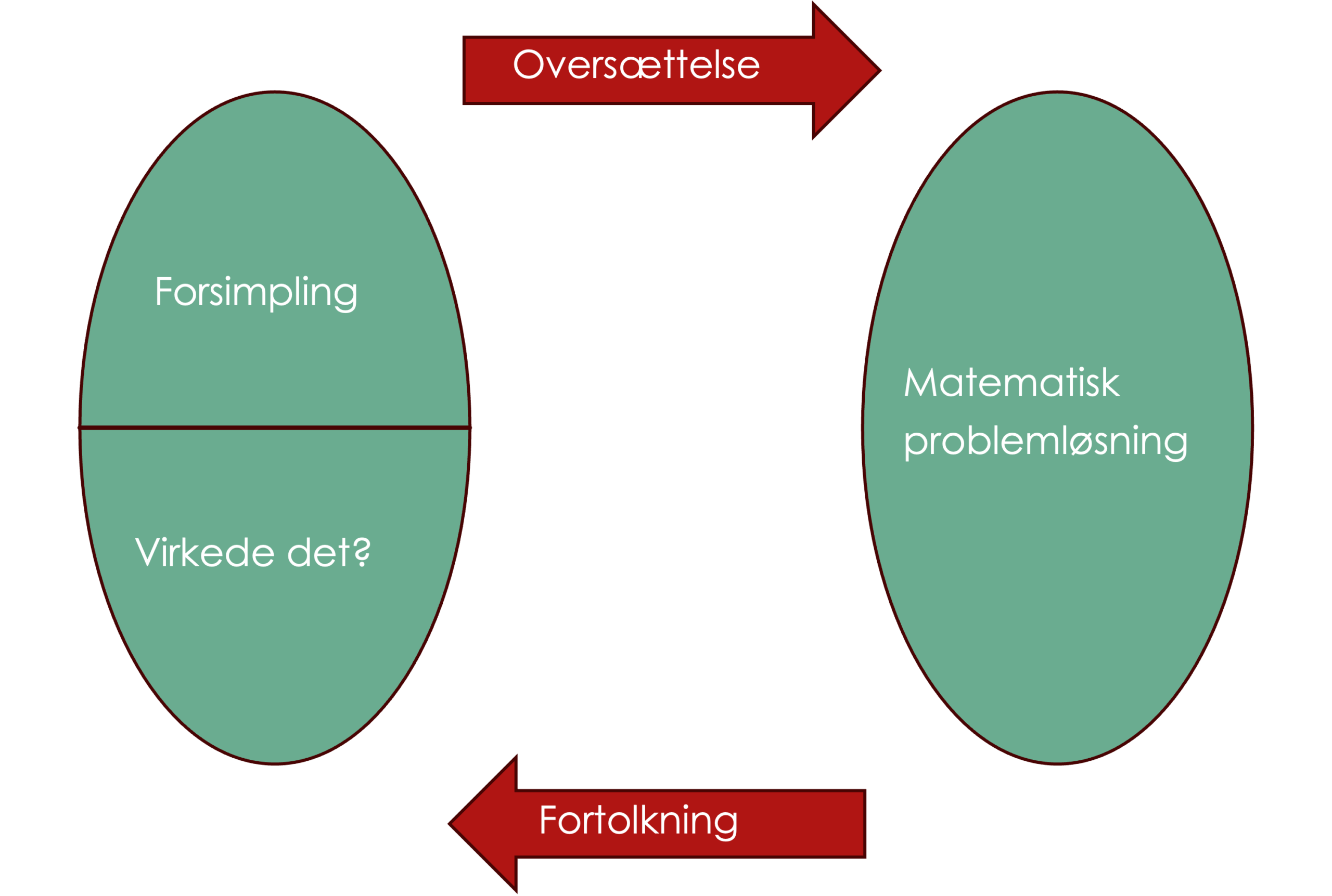
- Hvor kan de forskellige dele af øvelse 4 placeres i modelleringcyklussen?
- Skulle man for eksempel have valgt noget andet end danceability og happiness i idealiseringsfasen?
Opsamling i klassen
Rasmus Pagh siger: “Det er ønskeligt at anbefale brugeren noget, der minder om emnet, de kigger på, men også noget, der kan give dem et andet perspektiv.”
- Hvordan kan det opnås?
Spotify anbefaler musik, som brugere med samme smag som dig godt kan lide.
- Hvad kan det betyde for nye ukendte kunstnere?
Tak for idag!